
VLSI-Lecture-09
数据通路
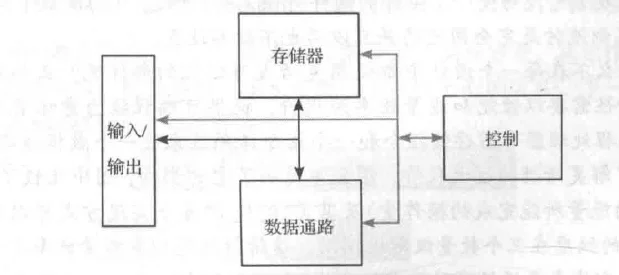
一般数字处理器的组成
首先需要建立设计复杂算术逻辑单元(ALU)或处理器数据通路时的方法论基础。在设计像加法器这样的复杂电路时,我们遵循以下核心原则:
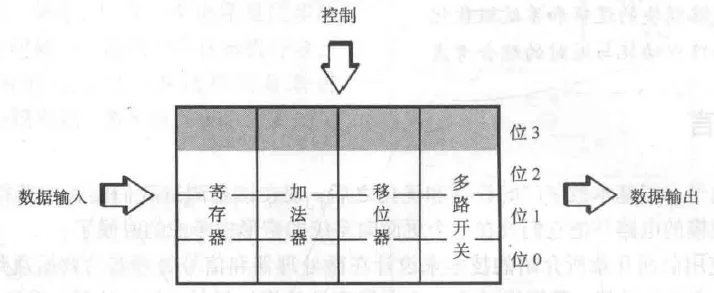
位片式数据通路结构
- 规整性 & 位片式实现:
为了处理位的数据,我们不需要设计种不同的电路,而是设计一个标准位片单元,然后将其复制次。
位片就是一个能够独立处理单位长度数据(可以是字节,字,也可能是比特)的完整功能模块(如xx位全加器,xx位寄存器,多路选择器等)。而位片式结构就是很多处理单位长度的数据的模块的叠加。
-
局域性:
- 指信号的交互主要发生在相邻的位片之间或模块内部。
运算往往是顺序执行或级联的。相邻连接体现了局域性,有利于减少长线互连带来的寄生效应和延迟。
-
正交性:
- 指 控制流 与 数据流 在几何结构和逻辑上的解耦。
-
层次化:
- 设计是分层进行的。从高位到低位,或从多位宽模块分解为少位宽模块。不同层次可以采用不同的物理实现方式,以平衡面积和速度。
-
模块化:
- 将功能封装为IP模块(如加法器、乘法器)。这使得设计可以像搭积木一样复用成熟的子电路。
加法器设计
加法是最常用的运算操作,也常常是限制处理器速度的元件。
| 结构 | 逻辑级数 | 最大扇出 | 布线通道 | 单元数 |
|---|---|---|---|---|
| Carry-Ripple | 1 | 1 | ||
| Carry-bypass (4段) | 2 | 1 | ||
| 平方根进位选择 | 1 | |||
| Brent-Kung | 2 | 1 | ||
| Sklansky | 1 | |||
| Kogge-Stone | 2 |
二进制加法器概述
基本单元
-
半加器:仅考虑两个本位输入 、,不考虑低位进位(也就是全加器的式子里把 全置为0)。由一个XOR门(产生Sum)和一个AND门(产生Carry)组成。
-
全加器:多位加法的基础,须处理三个输入:本位操作数 、 以及来自低位的进位输入 。输出为本位和 及向高位的进位输出 。
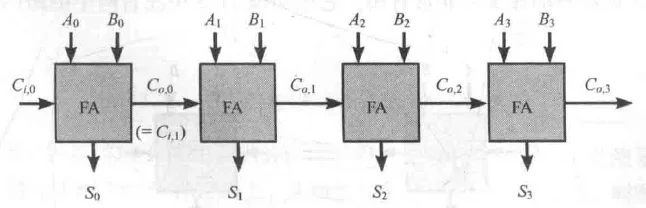
最基本的 — 逐位进位加法器
基本逻辑方程
全加器真值表
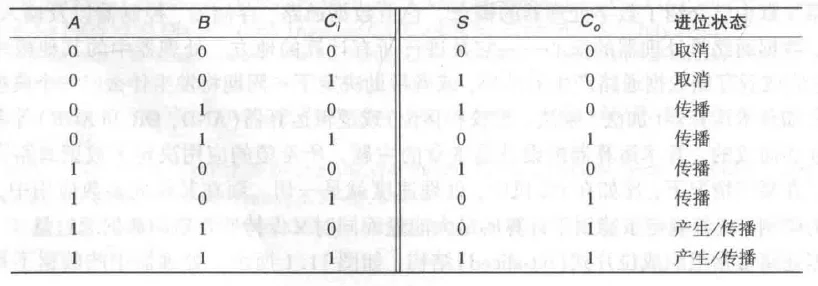
高速加法器基础:
| 类型 | 达成条件 | 表达式 | 说明 |
|---|---|---|---|
| Delete(进位消除) | 低位的进位 传到这一级会被消除,无论 是什么, 恒为0 | ||
| Propagate(进位传播) | 当 与 取值相异时,低位进位信号直接传播穿过这一级,,同时影响本级和下一级运算 | ||
| Generate(进位产生) | 该位主动产生一个新的进位信号向高位发送,无论 是什么, 恒为1 |
行波进位加法器
第 位的最终结果不仅取决于 ,还隐含地取决于 和 。
进位链:最高位的 必须==等待最低位的 经过所有中间位的处理==后才能确定。
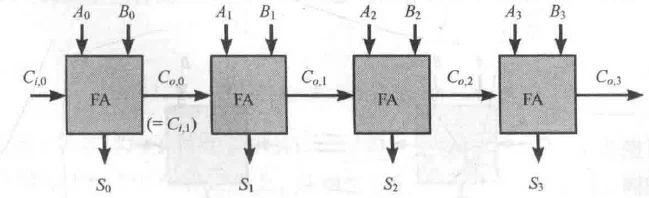
行波进位加法器
时序延迟
延迟时间公式:
最坏情况的延时与加数位数 N 成线性关系,即时间复杂度:。
意味着如果我们把位数翻倍,运算延迟将也增加一倍。在高速计算中是不可接受的瓶颈,因此设计的关键在于加快进位信号传播的速度。
进位信号的抽象重构
进位产生、进位取消、进位传播信号
| 类型 | 逻辑表达式 |
|---|---|
| G | |
| K/D | |
| P |
加法逻辑表达式重构
全加器的反向特性
标准的CMOS逻辑门(NAND, NOR)输出天然是反相的。要得到正逻辑(AND, OR),通常需要级联一个反相器。这会增加延时。
如果将全加器的所有输入 () 都取反,那么输出 () 也会自动变成原来输出的反码。此特性允许我们在处理反相信号时,不需要通过反相器将其恢复为正信号再运算,而是直接用反相信号进行运算,得到反相的结果。
单级全加器设计及优化
经典静态互补设计
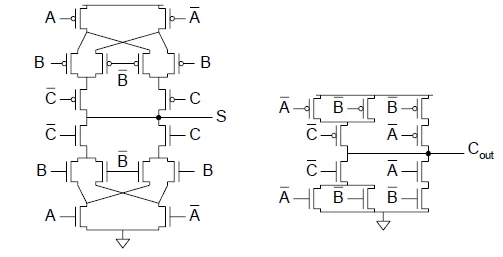
如果直接分别使用两套电路计算求和结果以及进位结果,晶体管统计:
| 项目 | 数量 | |
|---|---|---|
| S | 需 16 个管子 | |
| 需 10 个管子 | ||
| 反相器 | 3 个 | 需 6 个管子 |
| 总共 | 36个管子 |
记住这两个电路,非常经典。
无XOR复合门实现方案
利用 信号产生 ,省去了庞大的XOR门结构,总管子数降为28个:
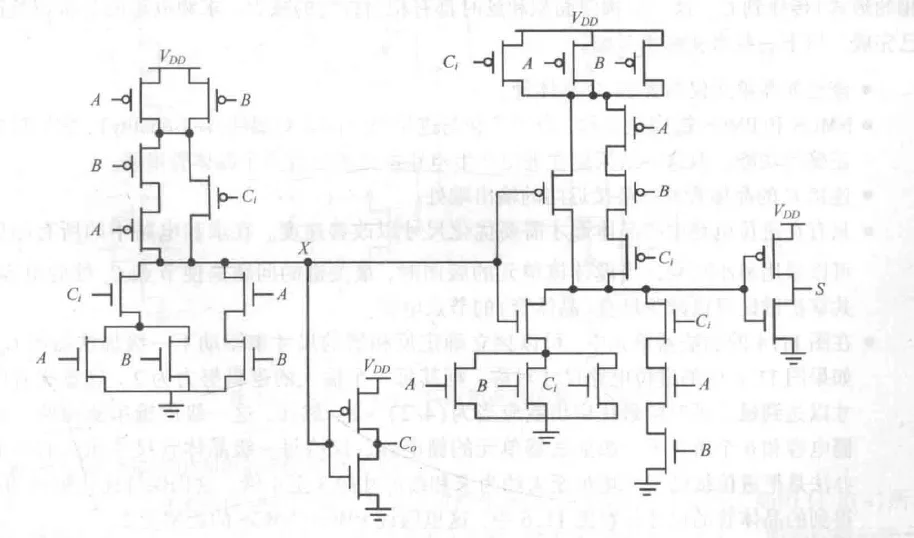
互补静态全加器实现电路(进位电路复用)
在本电路中,设计者利用了 信号来辅助生成 :
由于 是由 推导出来的,所以 的生成肯定晚于 ,但在行波进位加法器中,关键路径是进位链。只要 够快, 稍微慢一点是可以接受的(高位的 反正要等低位的 )。
信号连接的晶体管靠近输出节点
在串联的晶体管链中(如 NAND 的 PDN 结构),靠近地(GND)或电源(VDD)的管子开启后,内部节点需要先放电/充电。如果最晚到达的信号(通常是 )连接在最靠近输出端的晶体管,那么在它到达之前,之前的内部节点已经完成了预充放电,一旦它开启,输出端能以最快的速度翻转。这是减少Elmore Delay的标准做法。
劣势:
节点电容负载超大导致时间常数增大,让充放电时间变长,导致进位信号传播变慢。
负载组成:
-
本级负载:进位输出反相器的源漏扩散电容。
-
内部耦合:因为 的生成依赖 ,所以 还要驱动本级内部产生 的电路。
-
下一级负载:驱动下一级全加器的6个栅电容 (数一下一级全加器正好是六个的输入端) 以及级间连线的布线电容 。
消除输出反相器的行波进位加法器
目的:
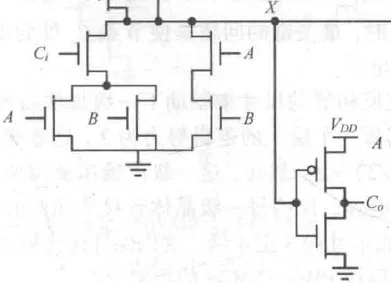
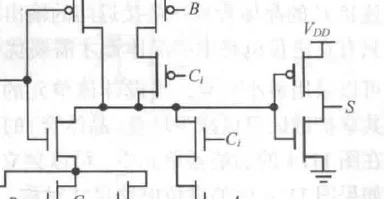
之前的进位/求和结果输出是带反相器的
这两个反相器会或多或少影响延时,因此可以利用全加器的反相特性来减免这两个延时(主要是减少进位链的延时,求和结果减不减无所谓)。
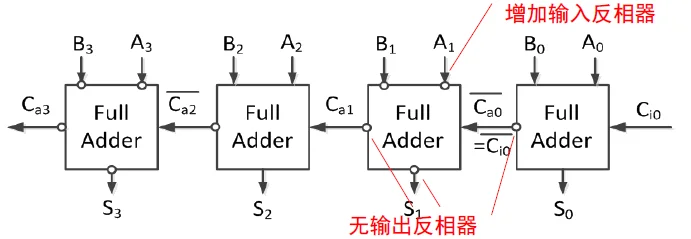
消除输出反相器的行波进位加法器
0级全加器直接去除进位反相器,1 级的全加器把输入也变成反的,由于取消了输出反相器,所以全加器把进位信号再次取反,回到了正的进位信号。如此奇偶交替则逻辑正确,速度也变快了。
镜像加法器
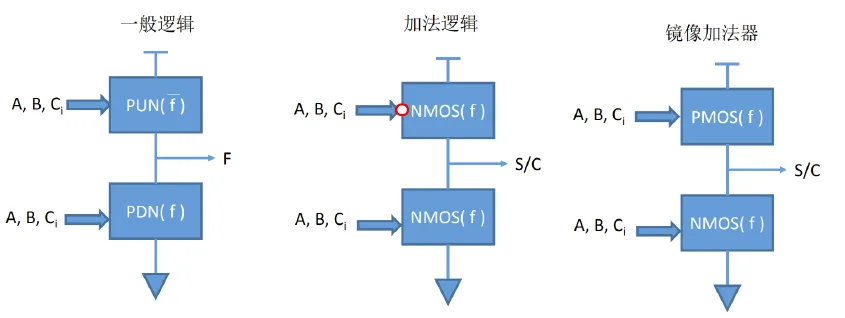
镜像电路演变过程
一般的静态互补逻辑如左图所示,上下需要设计不同的拓扑电路结构以满足同输入下拥有正好相反的导通结果,但是加法逻辑不一样,只需要把输入反过来(即输入添加一个反相器),就可以让一个拓扑电路结构重复使用。
然而正好 PMOS 和 NMOS 的导通逻辑相反,所以直接反相器也不用加了,直接 PMOS 和 NMOS 镜像结构就能实现加法逻辑,当然,这个情况仅限于拥有反相特性的加法逻辑。
最后把管子数优化到 24 个。
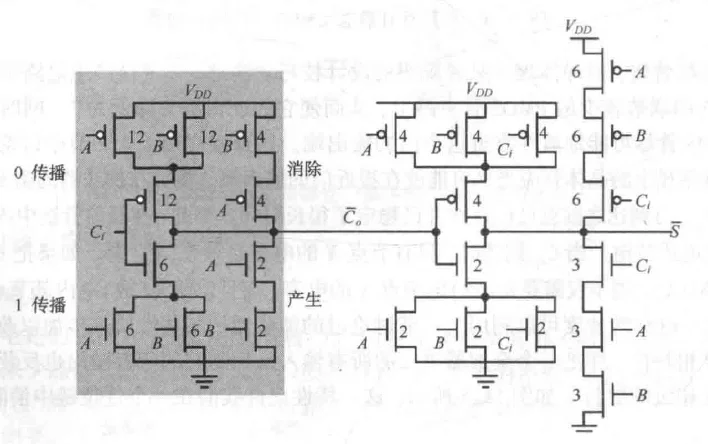
镜像加法器电路图
记住这个电路,也很重要。
传输门加法器
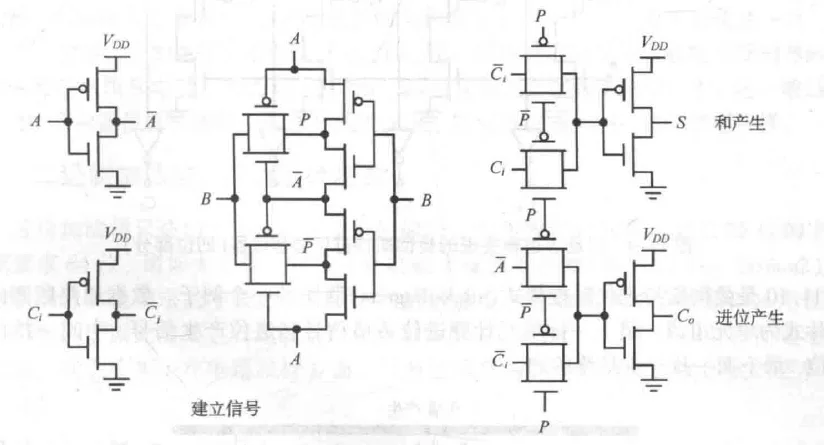
传输门加法器电路图
P set-up 电路的左半边不是很理解, 和 都会多加一份没必要的逻辑?
特点:
-
24个晶体管:与镜像加法器数量持平,具有较高的面积效率。
-
时序对称性: 和 的延时时间相同,从结构来看也是高度对称的。
高速进位链设计
曼彻斯特进位门
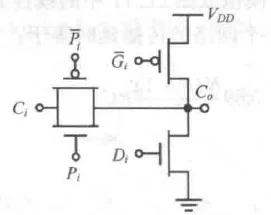
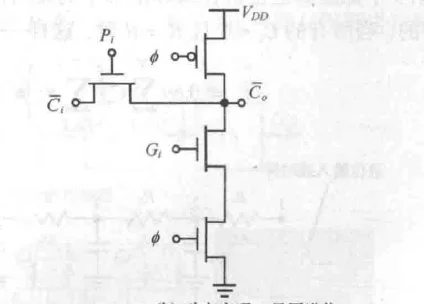
静态、动态曼彻斯特进位门
彻底利用抽象的进位标志来传播进位,而且使用了传输门逻辑,电路还是好理解的,而且加法逻辑的互斥性保证两个进位标志不会同时为 1,防止充放电冲突。
曼彻斯特进位链
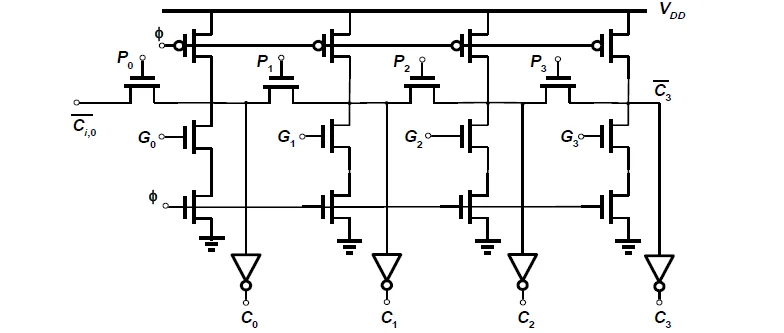
曼彻斯特进位链
曼彻斯特进位链呈现出多米诺风格的级联结构。
进位链传输管只用N管,节点电容很小,为四个扩散电容。
根据Elmore延时模型,级曼彻斯特进位链的延时:
进位选择加法器
概述
注意这是加法块之间的进位传递优化,针对的加法数据也是大位宽的数据。
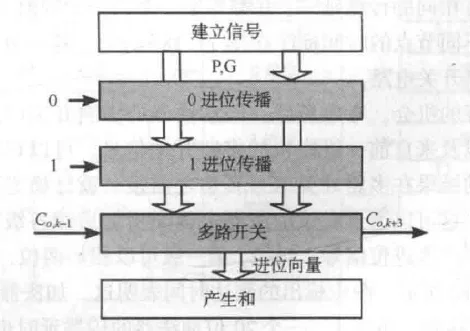
进位选择加法器设计蓝图
动机: 在传统的行波进位加法器中,第 级(假设分为4位一级)必须等待第 级的进位输出 到达后才能开始有效计算。为了打破这种等待,我们采用预测的方法(有点像微机原理的分支预测),硬件开销增加了约30%。
双路径并行计算
由于输入进位 只有两种可能性(“0”或“1”),对于每一位的加法,两条独立的进位传播路径:
-
“0” 进位传递:假设本级进位输入为 0,预先计算出一套结果(和与进位输出)。
-
“1” 进位传递:假设本级进位输入为 1,预先计算出另一套结果。
-
设置电路:用于生成所有位所需的 和 信号,供上述两条路径使用。
进位选择是分块双路而非全局裂变:每一块只需为当前的 (0或1)准备两套剧本,前级送来的进位只是一个负责二选一的‘开关’,它在每一级末尾都把状态收敛回了‘1’,所以没有引爆指数级。
每一级使用一个 选择剧情走向即可。
线性进位选择加法器
关键路径分析
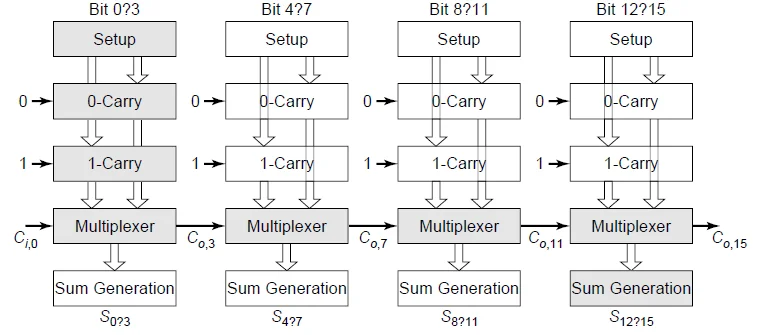
如图一共是计算 16 位数(即总位数 )的运算,分成 4 块 4 位(即分块位数 )的加法。
- 解释: 总时间 = 准备时间(所有块一起准备,所以算作1个) + M 个 块内进位传递时间(块内是线性)+ 个选择器时间 + 最后的求和时间
对比传统行波加法器的 延迟,这里虽然项中仍含有 ,==但 通常远小于 ,因此速度有显著提升==。
信号时间分配不均衡
在线性进位选择加法器中,我们将 位加法器划分为固定长度(例如均为 位)的块。
每个块内部的两条进位链是并行计算的。内部计算在 时刻就已经完成了。
进位链的结果在多路开关信号到达之前很久就已经稳定下来。因此使这两条路径的延时相等是有意义的。
平方根进位选择加法器
既然高位模块必须等待更久的 MUX 信号,那么不妨让高位模块承担更多的计算任务(处理更多位数,比如每高一级就多算一位)。
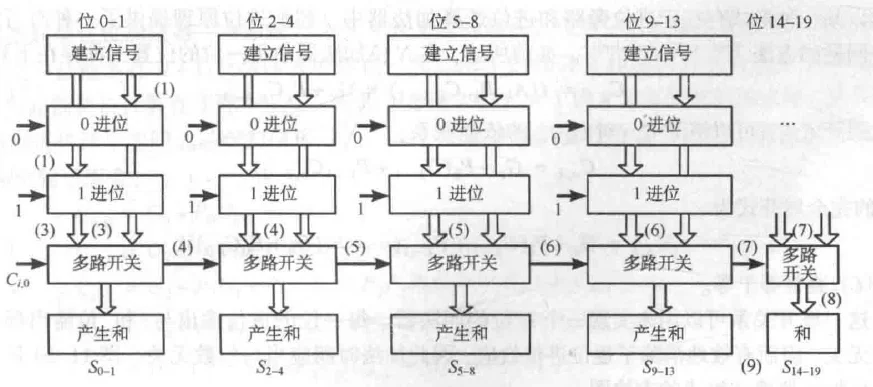
平方根进位加法选择器
于是总位数 变成了一个等差数列求和:
经求和公式推导,得出近似关系:==如果 很大,。(P 就是MUX链的长度,也就是级数)==
因此,总延时表达式修正为:
此时延时正比于 (亚线性关系),而不是 (线性关系),当 很大时,延时几乎变为常数
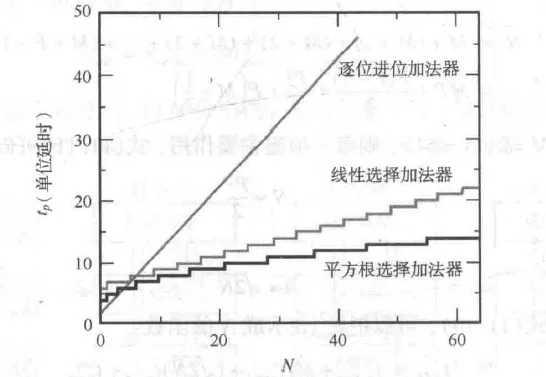
进位选择的优势
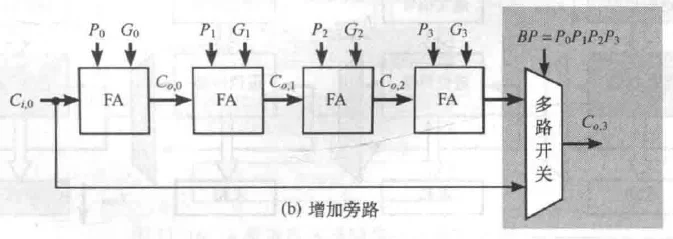
进位旁路加法器
相比于标准的行波进位加法器,只是在电路末端增加了一个MUX(硬件开销多了20%)。它的作用是决定最终输出的进位 是来自行波进位链的末端,还是直接来自输入进位 。
定义 为该块内所有进位传播信号的“与”逻辑,即
最坏情况分析:如果是 的情况(不能旁路或者差一位就旁路),或者虽然 但旁路路径延迟大于行波路径(在小位宽时可能发生),那么关键路径依然是传统的行波进位。此设计旨在优化超长距离进位传播。
关键路径分析
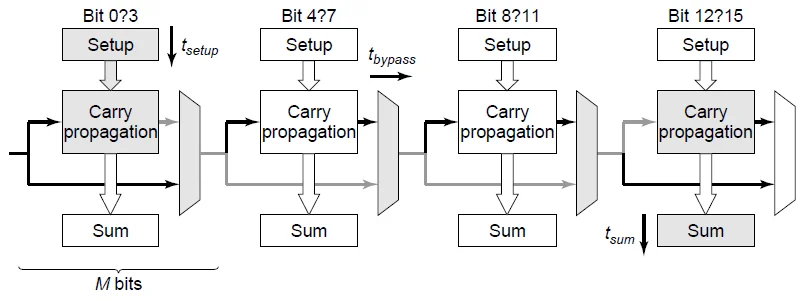
分块的进位旁路加法器
位加法器被分成 个组,每组 位。
总延时公式:
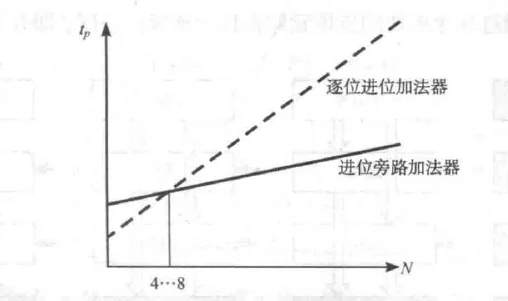
进位旁路加法器的优势 — 适合长距离,位数越大越好
一般N 在4~8 之间采用旁路进位。
超前进位加法器
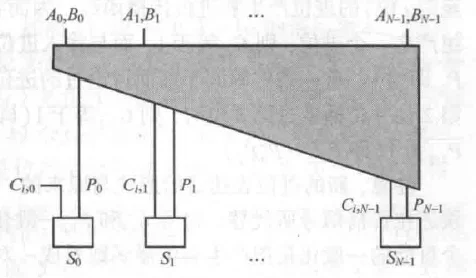
超前进位加法器原理图
每一位的进位输出只与最初的进位输入有关,而与比它低位的其他进位输入无关:
展开:
可见,进位输出的运算可以变成递归链,一直递归到最底层的输入进位 。
理论上,第1位和第32位的进位是同时计算出来的(理想化的 时间复杂度结论,实际的延时至少随位数线性增加)
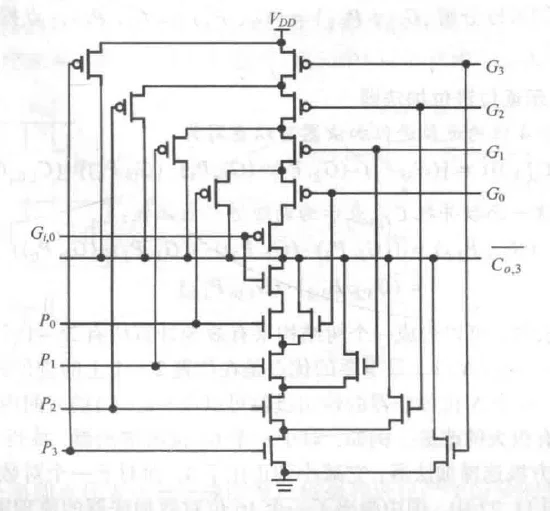
镜像-4位超前进位加法器
缺陷
-
大扇入导致速度变慢:
- 图中最左侧的NMOS支路是5个晶体管串联。串联的晶体管越多,等效电阻 越大,同时内部节点电容增加,导致放电时间 急剧增加。
-
大扇出导致延时加大:
-
最低位的信号(如 )参与了所有高位进位的计算。意味着 信号源需要同时驱动第1位、第2位……直到第N位的进位生成电路。驱动的负载电容(栅电容)巨大。
-
为了驱动这么大的负载,信号源必须非常强,或者插入巨大的缓冲器,这本身就会带来巨大的延时。
-
-
面积膨胀:
- 实现 位CLA所需的晶体管数量并不是随 线性增长的,而是接近几何级数或平方级增长。对于大位宽,其版图面积将变得不可接受。
树形加法器
似乎是选修章节,暂且不整理这部分的笔记了。